



Este post apareceu originalmente na minha coluna no site jornalismo orientado por dados.
No meu último post eu falei sobre como a regressão pode ser uma ferramenta útil para separar as diferentes relações entre as variáveis correlacionais. Eu também falei sobre como as aberrações podem ser problemáticas. Uma maneira de lidar com um outliers é simplesmente eliminá-lo da análise. Fazer isso diminui o poder estatístico (a probabilidade de encontrar um preditor significativo quando ele existe) e remove informações potencialmente valiosas do modelo. Poderia ser um esforço mais frutífero, pois informações valiosas podem ser obtidas. Fiz isto em meu posto sobre como Washington, DC difere dos outros estados e me deu uma idéia para outra covariada que deveria ser considerada além daquelas já consideradas: concentração de grupos de ódio, % sem seguro, % com bacharelado ou superior, e % na pobreza.
No meu postar sobre as características de Washington, DC como um outlier Descobri que é o menos branco em comparação com qualquer um dos estados considerados. Apenas 40,2% da população dos distritos se identifica como branco ou caucasiano lá. Somente o Havaí tinha um % branco menor em 25,4%. Na votação de saída para a eleição do ano passado, 60% de mulheres brancas sem formação universitária votaram no Trump enquanto 71% de homens brancos sem formação universitária votaram no Trump. 74% de não-brancos votaram em Clinton.
Acrescentando isso ao modelo melhorou significativamente a precisão do modelo com CC incluído com 78,5% da variabilidade do voto do Trump contabilizado. As variáveis para grupos de ódio e pobreza % não foram significativas e foram excluídas, pois tê-las no modelo diminui o poder estatístico. As variáveis % solteiro, % branco e % sem seguro foram significativas (o que significa que o valor p é inferior a 0,05 eu explicarei em um posto futuro), as outras não foram. O resultado da maioria dos pacotes estatísticos:
|
78.5% da variabilidade contabilizado |
Coeficientes |
Erro Padrão |
t Stat |
P-valor |
Baixar 95% |
Alto 95% |
|
Interceptar |
51.55 |
8.92 |
5.78 |
5.75E-07 |
33.61 |
69.48 |
|
% bacharelado ou superior |
-1.11 |
0.15 |
-7.55 |
1.2E-09 |
-1.41 |
-0.82 |
|
% Branco |
0.31 |
0.06 |
4.95 |
1.01E-05 |
0.18 |
0.43 |
|
% não segurado |
0.74 |
0.26 |
2.86 |
0.006319 |
0.22 |
1.26 |
A coluna rotulada "coeficientes" fornece os valores estimados para a equação de regressão que escrevi em posts anteriores. A equação atual lê-se:
Trunfo % da votação = 51,55 - 1,11*(% bacharelado) + 0,31*(% branco) + 0,74*(% não segurado)
Isto diz que quando todos os covariáveis são iguais a zero, prevê-se que Trump tenha 51.55% da votação. Para cada aumento de 1% nos bacharéis do % há uma diminuição estimada de 1.11% na votação do Trump. Para cada 1% de aumento da população branca do % no estado há um aumento estimado de 0,31% e para cada 1% de aumento do % não segurado no estado.
A coluna rotulada "erro padrão" é uma estimativa da incerteza dos coeficientes. A coluna rotulada "t stat" é a estatística de teste para determinar se os coeficientes são significativamente diferentes de zero. O "p-valor" é a probabilidade estimada de observar este coeficiente estimado quando o coeficiente verdadeiro é zero. Por convenção, quando o valor p é inferior a 0,05, concluímos que o coeficiente verdadeiro é diferente de zero. As duas últimas colunas mostram os limites superior e inferior para um intervalo de confiança de 95% para um coeficiente. O intervalo de confiança diz que 95% do tempo em que as estimativas são feitas, o verdadeiro coeficiente estará entre os limites superior e inferior. Neste caso, se os limites superior e inferior não se sobrepõem ao número zero, isso equivale ao coeficiente ser significativamente diferente de zero.
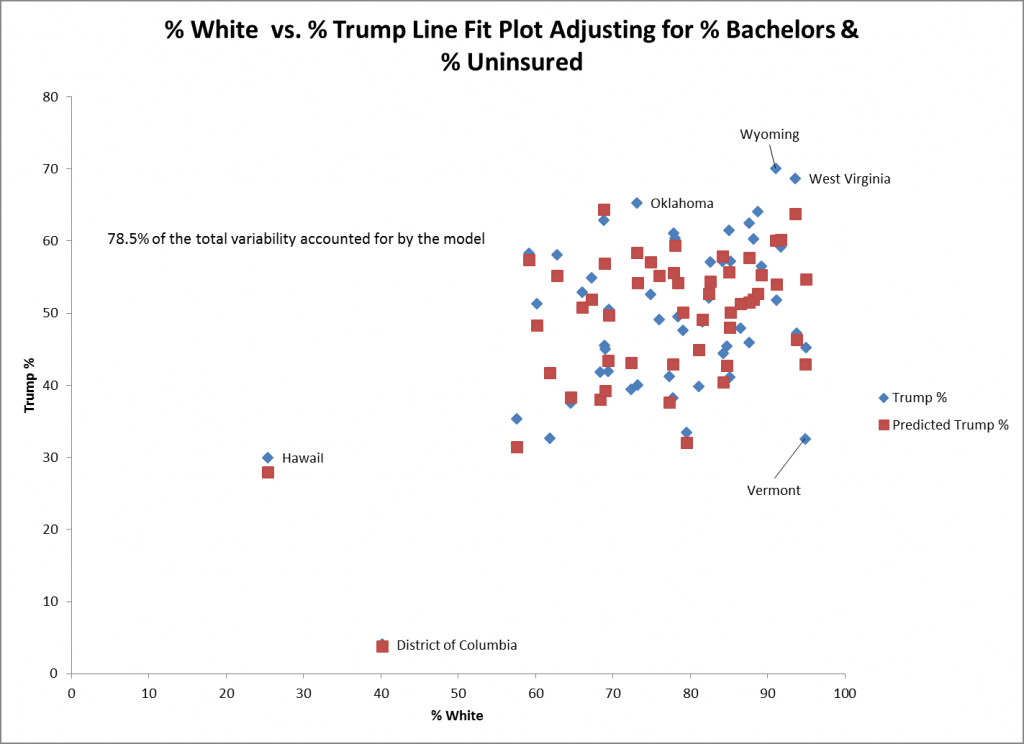
O gráfico de dispersão acima mostra os valores reais (no diamante azul) e previstos (nos quadrados vermelhos) para o % branco e % Trump para o modelo de ajuste para solteiros % e % não segurado. Os valores reais e previstos para o Distrito de Columbia (DC) e Havaí estão muito próximos um do outro, o que sugere um bom ajuste. Um estado que não se ajusta bem é Vermont, onde o voto real para Trump é 10% inferior ao voto previsto que pode ser visto diretamente acima do diamante azul para Vermont.
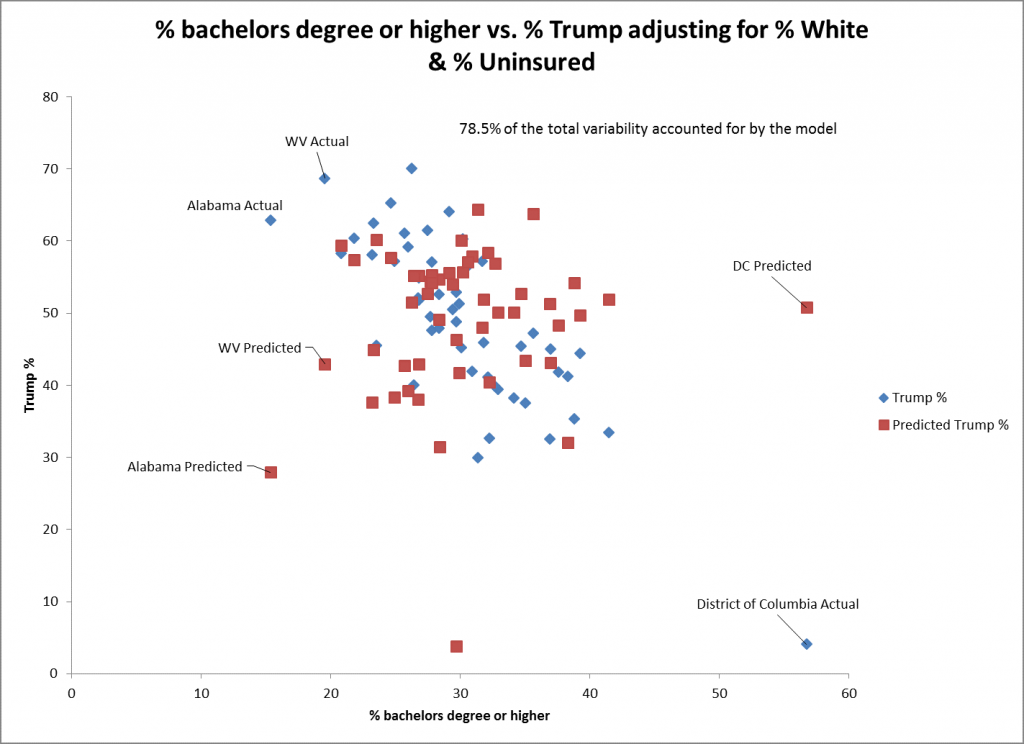
O gráfico de dispersão para o bacharelado do % ou superior sugere que o ajuste não é tão bom quanto para o do % branco como o preditor. Isto se reflete no maior erro padrão para este preditor (0,15) do que para o % branco (0,06). A previsão para DC não é tão boa para este preditor como é para o mais alto. A tendência ainda é significativa na direção negativa.
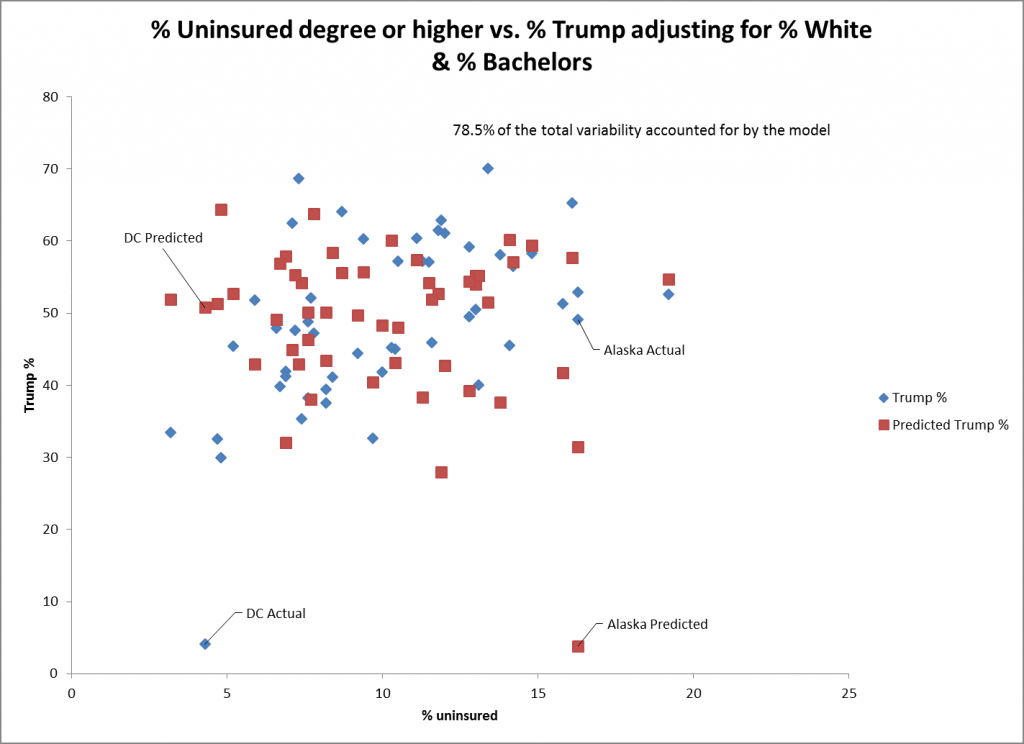
O gráfico de dispersão para o % não segurado como preditor mostra ainda menos apto para o % da Trump da votação. DC e Alasca são pontos pouco adequados para este preditor, entre muitos outros estados. O erro padrão para este preditor mostra ainda menos apto (0,26) para os outros preditores, embora ainda seja estatisticamente significativo.
A regressão múltipla é uma ferramenta potencialmente poderosa para separar as relações entre as variáveis preditoras para um resultado específico quando conduzida corretamente. Adicionar os covariáveis certos, como a raça, pode ajudar a aliviar os efeitos de um outlier, como Washington, DC. É sempre melhor incluir todos os dados para dar o quadro mais completo possível.
Vemos agora que como o % da população de um estado com bacharelado ou superior aumenta o % do voto para Trump diminui. Ao mesmo tempo, como as porcentagens de brancos e não segurados em um estado, aumenta o % do voto para Trump. Na presença dessas variáveis, a concentração de grupos de ódio e o % do estado na pobreza não são mais preditores significativos do voto do Trump.
Enquanto Trump e o congresso controlado pelos Republicanos se preparam para revogar a Lei de Cuidados Acessíveis (ACA ou como o Partido Republicano diz Obamacare), o Escritório de Orçamento do Congresso estima que 23 milhões de americanos perderão seu seguro de saúde na versão da Câmara dos Deputados do projeto de lei e um número estimado de 22 milhões o perderá na versão do Senado. Neste modelo, a taxa de não segurados em cada estado está positivamente correlacionada com o voto de Trump. Trump acredita que o aumento da taxa não segurada aumentará sua participação no voto em 2020?
A pobreza não estava associada ao voto do Trump em 2016. A diminuição das estimativas não seguradas desde que a ACA entrou em vigor em 2014 se deve principalmente à expansão da Medicaid para os indivíduos mais pobres e aos subsídios que permitem aos indivíduos de menor renda adquirir seguros de saúde. Aumentar o número de não segurados pode não diminuir o voto da Trump, mas é pouco provável que aumente.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


