



Data is ubiquitous in salud—from hospitals, laboratories and investigación centres to surveillance systems, data makes up an indiscriminate part of healthcare systems. In fact, there is a myriad of types of data in biosciences research collected through clinical research or generated by genome sequencing or computational drug modelling. Investigación sobre el cáncer in particular benefits from the applications of big data and analytics. Cancer screening programs initiate rich repertoires of imaging and laboratory data, which require in-depth analysis and repeated testing in order for real value to be derived from it. Repeated testing and análisis de datos enable clinical researchers to develop better drugs, understand their attributes in vivo y producir nuevos tipos de fármacos para combatir el cáncer.
No es un secreto que datos masivos se considera como el método seguro para descifrar la complejidad del cáncer. La necesidad de establecer nuevos mecanismos para tratar el cáncer ha llevado a las empresas a investigar herramientas de visualización y análisis de datos. Capturar, recopilar, almacenar y analizar los datos de las células cancerosas es un juego completamente nuevo en el que IA benévola, 10X Genómica, Medicina Insílica y NuMedii han alcanzado sus primeros hitos. In fact, 10X Genomics has gone the extra mile to provide whole genome sequencing, exome sequencing and single cell transcriptome analysis services that vividly indicate cancer-prone gene sequences in the DNA, mRNA and polypeptide chains, respectively. Few others are utilizing broader data frameworks, novel screening mechanisms and high definition data filtering algorithms to test cancer drugs on a wide range of cellular environments.
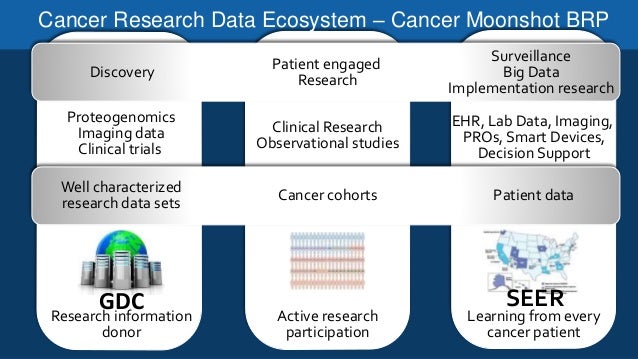
La aplicabilidad de los macrodatos en el diagnóstico, la experimentación y la gestión del cáncer está siendo aclamada como el paso vital hacia la investigación oncológica de siguiente nivel. He aquí 7 formas en las que el big data está influyendo en la investigación del cáncer.
1. Secuenciación de los genomas del cáncer en humanos

Todas las células de nuestro cuerpo tienen el mismo número de cromosomas y aproximadamente el mismo volumen de ADN. Pero las células cancerosas presentan distintas aberraciones en el contenido cromosómico y el crecimiento, que, si se someten a una visualización in silico, pueden utilizarse para aprovechar la información hasta el nivel del ADN. Estos estudios de secuenciación pueden ayudar a los biólogos celulares, bioinformáticos, biólogos moleculares y nanobiotecnólogos a desarrollar mejores métodos para eliminar las anomalías cromosómicas, lo que puede conducir a posibles vías terapéuticas.
2. Secuenciación de alto rendimiento de muestras de pacientes
Estamos en la época en la que la medicina personalizada se está convirtiendo en algo habitual en la asistencia sanitaria y el cáncer es el mayor campo de acción de ese progreso. Este empuje hacia la medicina personalizada ha hecho recaer en la biología computacional, la rama de la biología que hace que la asistencia sanitaria sea tan sofisticada como se ve hoy en día. Profesor Olivier Elementoexperto en medicina computacional de la Universidad de Cornell, subraya que, dado que las células cancerosas cambian constantemente, evolucionan y se adaptan al entorno humano, ahora es más necesario que nunca disponer de tecnologías de nueva generación más rápidas para descubrir la composición genética de un tumor. Y el esfuerzo no acaba ahí, hay que identificar las secuencias de mutación, segmentarlas y procesarlas en función del gen expresado.
3. Secuenciación de genomas de otros organismos
El primer genoma que se secuenció fue el de Escherichia coliun organismo unicelular. Entonces, los genomas de las plantas como Arabidopsis thaliana Se secuenciaron gusanos, reptiles y roedores no vertebrados. Con cada grado de complejidad que llevaban estos organismos, la secuenciación del genoma se hizo más grande en cuanto a la comprensión del potencial de una sola célula para controlar, sensibilizar o alejar las células cancerosas. También presentó teorías de trabajo detrás de los desencadenantes del cáncer. En la actualidad, los investigadores están analizando datos en tiempo real de líneas celulares de cáncer de ovario de ratón/pollo para aumentar o mejorar los métodos de detección del cáncer, además de aumentar la precisión de las pruebas de cribado actualmente disponibles.
4. Análisis del transcriptoma para un mejor seguimiento del cáncer
En la última década se han generado grandes bases de datos de cribado y datos experimentales sólo durante los estudios relacionados con el cáncer. Esto ha añadido un valor crucial para mantener los genes marcadores que ahora son las herramientas de primera mano para el seguimiento de oncogenes, el descubrimiento de fármacos y los estudios de biocompatibilidad. Además, algunas empresas extrapolan los datos del genoma del cáncer para analizar los transcriptomas y la síntesis de proteínas. Esto es la clave para encontrar fragmentos de genes mal colocados y sus productos, por lo que ayuda a rastrear las mutaciones, tanto las conservadoras como las no conservadoras.
5. Incorporación de algoritmos de aprendizaje automático para la elaboración de modelos de diagnóstico
Los sistemas sanitarios almacenan enormes cantidades de datos, que las tecnologías actuales han facilitado su utilización. Los investigadores biotecnológicos e interdisciplinarios están realizando vastos análisis de esas bases de datos mediante el uso de la alta velocidad algoritmos de aprendizaje automático que pueden explorar los datos, interactuar con ellos y garantizar la máxima precisión en la integración de grandes bases de datos. Se están empleando algoritmos de aprendizaje automático y sistemas de modelización de datos de alta tecnología para integrar los datos relacionados con el cáncer procedentes de distintas fuentes con el fin de obtener una imagen más amplia de los tumores. Las herramientas de visualización de datos genéticos están haciendo furor en la detección del cáncer al permitir nuevos métodos para comprobar el crecimiento de las células cancerosas y la muerte de las sanas. Esto se ha puesto en práctica de forma efectiva al incorporar el Sistema de Información de Modificación Genética e Investigación Clínica, que son los sistemas de gestión de datos de investigación de código abierto más eficientes para visualizar datos de secuenciación y cribado de alto rendimiento.
6. Presentar una mayor claridad en el pronóstico de la enfermedad
Algunas herramientas de software de visualización de datos sanitarios, como el CancerLinQ have been developed, which enable physicians and interventionalists to get access to high-quality patient medical data. This is important because it helps understand previous cancer incidences, the progression of the disease and the previous treatment regimen. Doctors are referring to protected medical data of patients using screening tools and using it to recommend ensayos clínicos, suggest personalized treatment protocols and decide the scope of cancer management more effectively. Nowadays, hospitals that report high admission rates for cancer patients have also started using Tarjetas de identificación del tumor que permiten que sus datos sean accesibles de forma centralizada para su evaluación clínica.
7. Los datos clínicos también presentan respuestas viables para las recaídas del cáncer
Cada vez son más los profesionales sanitarios que recurren a herramientas de análisis de datos para comprender las razones por las que algunos pacientes presentan tumores recidivantes y otros no. Los médicos están evaluando un gran número de informes de casos que ayudan a evaluar los riesgos para la salud de los pacientes con una perspectiva mucho más amplia que antes. Aunque los informes de casos médicos se utilizan desde hace mucho tiempo, es ahora cuando su accesibilidad y utilidad han aumentado. Esto significa que los datos de laboratorio no se someten a procesos de identificación estándar, sino que se evalúan tras compararlos con otros casos notificados a nivel mundial. Esto hace que los datos sean el requisito clave para el tratamiento personalizado.
El cáncer evoluciona a un ritmo superior al de nuestros medicamentos. Por ello, si se pretende vencerlo, controlarlo o prevenirlo, es imprescindible canalizar los esfuerzos con un mejor reconocimiento de objetivos. El big data es esa tecnología fundamental que un científico del cáncer debe aplicar para mejorar la calidad de la investigación y establecer los mejores resultados más rápidamente.
_______________________________________
Consulte a un investigación del cáncer specialist o freelance científico de datos en Kolabtree.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


