



Dieser Beitrag wurde verfasst von Paul Riccieinem Kolabtree-Experten. Es erschien ursprünglich in seiner Kolumne auf Datengesteuerter Journalismus.
Dieser Artikel beschreibt, wie der exakte Test von Fisher für Kontingenztabellen mit kleinen Stichproben verwendet werden kann. Ein häufiges Problem bei Datenanalyse ist die Frage, wie man feststellt, ob es eine statistische Beziehung zwischen zwei kategorialen Variablen wie Geschlecht, Rasse oder dem Stimmenanteil für zwei Kandidaten bei einer Wahl gibt. Am einfachsten lässt sich die Beziehung veranschaulichen, indem die Zählungen für jede Kombination von zwei Variablen in einer Kontingenztabelle dargestellt werden, wobei die Zeilen die Werte der einen Variable und die Spalten die Werte der anderen Variable darstellen. Der am häufigsten verwendete statistische Test für einen Zusammenhang zwischen den Zeilen- und Spaltenvariablen ist das Chi-Quadrat (χ2) Test. Das Beispiel in der nachstehenden Tabelle dient zur Veranschaulichung des Tests.
| Demokratischer Gewinner (% der Spalte) | Insgesamt | ||
| Clinton-Sieg | Sanders gewinnt | ||
| Trump 1. | 25 (86%) | 12 (55%) | 37 |
| Trump 2. | 3 (11%) | 8 (36%) | 11 |
| Trump 3. | 1 (3%) | 2 (9%) | 3 |
| Insgesamt | 29 (100%) | 22 (100%) | 51 |
Die Spalten in der obigen Tabelle zeigen die Vorwahlen, die Hillary Clinton und Bernie Sanders auf Seiten der Demokraten gewonnen haben, und die Platzierungen von Donald Trump in denselben Vorwahlen auf Seiten der Republikaner. Die Gesamtzahl der Staaten in der Tabelle beträgt 51, da der District of Columbia mit eingerechnet ist. Die Prozentzahlen in den Spalten zeigen, dass Trump 86% der Vorwahlstaaten gewonnen hat, die Clinton gewonnen hat, während er 55% der Staaten gewonnen hat, die Sanders gewonnen hat.
Der Chi-Quadrat-Test basiert auf der Berechnung der erwarteten Werte für jede Zelle in der Tabelle. Der erwartete Wert (der Wert für die Zelle, den man erwarten würde, wenn es keine Beziehung zwischen den Variablen gäbe) für die Zelle für die Staaten, in denen Trump auf republikanischer Seite den dritten Platz belegte, und für die Staaten, in denen Bernie Sanders auf demokratischer Seite gewann, würde beispielsweise berechnet, indem die Zeilensumme für den dritten Platz von Trump (3) mit der Spaltensumme für die Staaten, in denen Sanders gewann (22), multipliziert wird. Dieses Produkt wird dann durch die Gesamtzahl der Beobachtungen für (51) geteilt. Die Formel für den Erwartungswert lautet wie folgt:
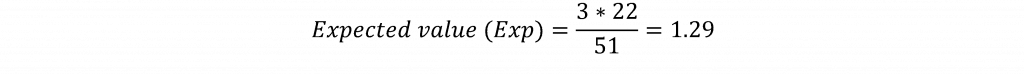
Das bedeutet, dass für diese Zelle ein Wert von 1,29 zu erwarten wäre, wenn die Vorwahlstaaten, in denen Trump Dritter wurde und Sanders gewann, völlig unabhängig voneinander wären. Der beobachtete Wert für diese Zelle ist 2, was darauf hindeutet, dass die Zählung für diese Zelle höher ist als zu erwarten wäre. Die erwarteten Werte werden für jede Zelle in der Tabelle berechnet, und die Differenz zwischen den beobachteten und den erwarteten Werten für jede Zelle wird berechnet, quadriert, durch den erwarteten Wert geteilt und gemäß der Formel über die Zellen in der Tabelle summiert:
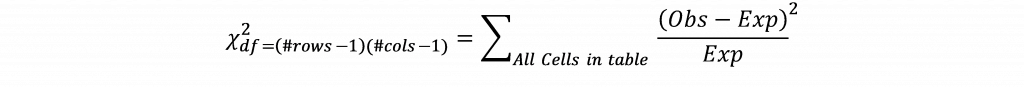
Wenn der Wert für das Chi-Quadrat den kritischen Chi-Quadrat-Wert für einen gegebenen Freiheitsgrad (ermittelt durch Multiplikation der Anzahl der Zeilen minus eins und der Anzahl der Spalten minus eins) und den p-Wert übersteigt, wird auf einen Zusammenhang zwischen den Variablen geschlossen.
Es gibt ein Problem mit dem Chi-Quadrat-Test. Es handelt sich um eine Annäherung an die Verteilung der Zählungen in Kontingenztabellen. Wenn mehr als 20% der Zellen in der Tabelle einen Erwartungswert von weniger als fünf haben, funktioniert die Chi-Quadrat-Annäherung nicht, um die Hypothese einer Assoziation zwischen der Zeilenvariablen und der Spaltenvariablen zu testen (wie es in der Tabelle unten der Fall ist). Beide Variablen in der Tabelle sind kategorisch. Die wichtigsten Statistikpakete warnen den Benutzer, wenn diese Annahme verletzt wird. Ein Verstoß gegen die Annahme führt dazu, dass der beobachtete p-Wert nicht korrekt ist und kann zu falschen Schlussfolgerungen hinsichtlich des Vorhandenseins oder Nichtvorhandenseins eines Zusammenhangs führen. Es gibt eine exakte Alternative zum Chi-Quadrat-Test, den exakten Test von Fisher.
Der exakte Test von Fisher basiert auf der hypergeometrischen Wahrscheinlichkeitsverteilung.
![]()
Hier wird die Ri! sind die Fakultäten der Zeilensummen (5!=5*4*3*2*1), Ci! sind die Faktorielle der einzelnen Spaltensummen, N! ist die Fakultät der Gesamtsumme der Tabelle und die aij! sind die Faktoren für die einzelnen Zellenwerte. Die Πij ist der Produktkoeffizient der einzelnen Zellwerte. Eine solche Formel ist noch rechenintensiver als der Chi-Quadrat-Test, insbesondere bei Tabellen mit vielen Zeilen und Spalten. Aus diesem Grund wurde in der Vergangenheit der Chi-Quadrat-Test bevorzugt, weil er zu viel Speicherplatz für die Computer benötigte. Heutzutage ist die Ausführung des exakten Fisher-Tests für Computer weniger problematisch, und er lässt sich in den wichtigsten Statistikpaketen (R, SAS, SPSS) leicht ausführen, STATA, usw.).
Die Befehle zur Durchführung des exakten Tests nach Fisher und des Chi-Quadrat-Tests in R (einem kostenlosen Programm) sind unten für die Tabelle am Anfang des Artikels mit der entsprechenden Ausgabe zu sehen (gelb für den exakten Test nach Fisher, grün für den Chi-Quadrat-Test).
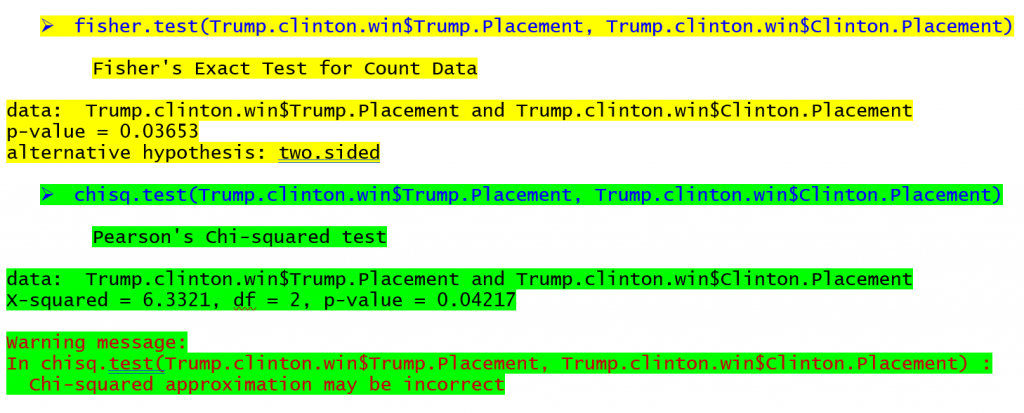
Die Ausgabe für den exakten Test nach Fisher zeigt, dass die Wahrscheinlichkeit, diese Tabellenhäufigkeiten zu beobachten, 0,03653 beträgt, wenn es keinen Zusammenhang zwischen den Zeilen und Spalten gibt. Die Ausgabe des Chi-Quadrat-Tests zeigt eine Wahrscheinlichkeit von 0,04217 für eine Beziehung in derselben Tabelle. Wenn wir den p-Wert von 0,05 als Kriterium für die Signifikanz verwenden würden, würden wir in diesem Fall eine Beziehung für beide Tests finden, obwohl die p-Werte unterschiedlich sind. In den Staaten, die Hillary Clinton in der Vorwahlsaison gewonnen hat, war die Wahrscheinlichkeit größer, dass Donald Trump gewinnt, während in den Staaten, in denen Bernie Sanders gewonnen hat, die Wahrscheinlichkeit größer war, dass Trump den 2.und oder 3rd Bei Tabellen mit noch kleinerem Stichprobenumfang kann der Unterschied zwischen den p-Werten noch größer sein, was zu völlig anderen Schlussfolgerungen führt.
Zur Warnung: Der p-Wert sollte nicht als Indikator für die Stärke des Zusammenhangs zwischen kategorialen Variablen verwendet werden. Entweder ist der Test signifikant oder nicht. Der p-Wert ist von der Stichprobengröße abhängig. Häufig wird das Odds Ratio zur Schätzung der Effektgröße verwendet, aber R berechnet es in der Funktion fisher.test nur für Tabellen mit 2 Spalten und 2 Zeilen.
Der exakte Test von Fisher bietet ein Kriterium, um zu entscheiden, ob die Unterschiede in den beobachteten Prozentsätzen zwischen zwei kategorialen Variablen in einer Stichprobe signifikant sind oder nur auf zufälliges Rauschen in den Daten zurückzuführen sind. Im obigen Beispiel sind die 86% der von Clinton und Trump gewonnenen Vorwahlen signifikant verschieden von den 55% der von Sanders und Trump gewonnenen Vorwahlen. Journalisten sollten immer vorsichtig sein, wenn sie nur die beobachteten Prozentsätze oder Auszählungen betrachten, da solche Entscheidungen subjektiv sind. Subjektive Entscheidungen können durch vorgefasste Meinungen über die mit den Daten zusammenhängenden Fragen weiter getrübt werden.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


