



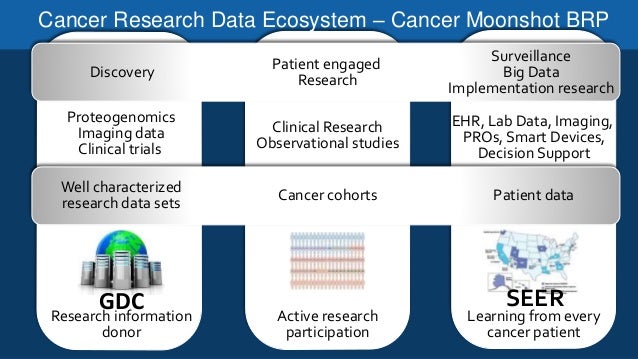
Data is ubiquitous in healthcare—from hospitals, laboratories and research centres to surveillance systems, data makes up an indiscriminate part of healthcare systems. In fact, there is a myriad of types of data in biosciences research collected through clinical research or generated by genome sequencing or computational drug modelling. Cancer research in particular benefits from the applications of big data and analytics. Cancer screening programs initiate rich repertoires of imaging and laboratory data, which require in-depth analysis and repeated testing in order for real value to be derived from it. Repeated testing and data analysis enable clinical researchers to develop better drugs, understand their attributes in vivo and produce novel drug types for tackling cancer.
It’s no secret that big data is considered as the sure-shot method to break down the complexity of cancer. There is an urge to establish novel mechanisms to treat cancer, which has led companies to investigate data visualization/analysis tools. Capturing, collecting, storing and analysing data form cancer cells is a whole new ballgame in which Benevolent AI, 10X Genomics, Insilico Medicine and NuMedii have achieved their first milestones. In fact, 10X Genomics has gone the extra mile to provide whole genome sequencing, exome sequencing and single cell transcriptome analysis services that vividly indicate cancer-prone gene sequences in the DNA, mRNA and polypeptide chains, respectively. Few others are utilizing broader data frameworks, novel screening mechanisms and high definition data filtering algorithms to test cancer drugs on a wide range of cellular environments.
Big data’s applicability in cancer diagnosis, experimentation and management is being hailed as the vital step towards next-level cancer research. Here are 7 ways big data is impacting cancer research.
1. Sequencing Cancer Genomes of Humans

Every cell of our body has the same number of chromosomes and about the same volume of DNA. But cancer cells exhibit distinct aberrations in the chromosomal content and growth, which, if subjected to in silico visualization, can be used to harness information down to the DNA level. These sequencing studies can help cell biologists, bioinformaticians, molecular biologists and nanobiotechnologists develop better methods to remove chromosomal abnormalities, which can lead to possible therapeutic routes.
2. High-Throughput Sequencing of Patient Samples
We’re in the age when personalized medicine is becoming commonplace in healthcare and cancer is the biggest scope for that progress. This push towards personalized medicine has put the onus on computational biology, the branch of biology that makes healthcare as sophisticated as it is viewed today. Professor Olivier Elemento, a Computational Medicine expert at the Cornell University highlights that as cancer cells are always changing, evolving and adapting to human environments, quicker next-generation technologies are more necessary now than ever to uncover a tumour’s genetic makeup. And the effort doesn’t just end there, mutation sequences have to be identified, segmented and processed with regards to the gene expressed.
3. Sequencing Genomes of Other Organisms
The first genome to be sequenced was of Escherichia coli, a unicellular organism. Then, plant genomes like Arabidopsis thaliana and non-vertebrate worms, reptiles and rodents were sequenced, With every degree of complexity that these organisms carried, genome sequencing gained bigger in terms of the understanding of a single cell’s potential to control, sensitize or ward off cancerous cells. It also presented working theories behind triggers of cancer. Now, researchers are analysing real-time data from mouse/chicken hamster ovary cancer cell lines to augment or improve cancer detection methods, along with increasing the accuracies of presently available screening tests.
4. Transcriptome Analysis for Better Cancer Monitoring
Large databases of screening and experimental data have been generated only during cancer-related studies in the last decade. This has added crucial value to maintain marker genes that are now the first-hand tools for oncogene monitoring, drug discovery and biocompatibility studies. Moreover, some companies extrapolate cancer genome data to analyse transcriptomes and protein synthesis. This is the key to finding misplaced gene fragments and their products, so this helps to track mutations, both conservative and non-conservative ones.
5. Incorporating Machine Learning Algorithms For Diagnostic Modelling
Healthcare systems store enormous amounts of data, which modern day technologies have made it easier to utilize. Biotech/interdisciplinary researchers are performing vast analyses of those databases using high-speed machine learning algorithms that can scan data, interact with data and ensure the highest accuracy in the integration of large databases. Machine learning algorithms and high-tech data modelling systems are being employed to integrate cancer-related data from different sources in order to get a bigger picture of tumours. Genetic data visualization tools are making waves in cancer detection by enabling new methods to check cancer cell growth and death of healthy cells. This has been effectively put into use by incorporating the Genetic Modification and Clinical Research Information System, which are the most efficient open source research data management systems to visualize high throughput sequencing and screening data.
6. Presenting Greater Clarity on Disease Prognosis
Some healthcare data visualization software tools such as the CancerLinQ have been developed, which enable physicians and interventionalists to get access to high-quality patient medical data. This is important because it helps understand previous cancer incidences, the progression of the disease and the previous treatment regimen. Doctors are referring to protected medical data of patients using screening tools and using it to recommend clinical trials, suggest personalized treatment protocols and decide the scope of cancer management more effectively. Nowadays, hospitals that report high admission rates for cancer patients have also started using Tumour ID cards that enable their data to become centrally accessible for clinical evaluation.
7. Clinical Data also Presents Viable Answers for Cancer Relapses
More and more healthcare providers are turning to data analytics tools to understand the reasons why some patients show relapsing tumours while others don’t. Doctors are evaluating large numbers of case reports that help assess patient health risks in a much wider perspective than before. While medical case reports have been in use for a long time, it’s only now that their accessibility and utility have been rising. This means laboratory data are not subjected to standard identification processes but assessed after comparing with other globally reported cases. This makes data the key requirement for personalized treatment.
Cancer is evolving at higher rates than our medicines. Hence, if you’re aiming to defeat, control or prevent it, it’s imperative to channelize the efforts with better target recognition. Big data is that pivotal technology a cancer scientist should apply to improve the quality of research and establish the best results quicker.
_______________________________________
Consult a cancer research specialist or freelance data scientist on Kolabtree.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


